

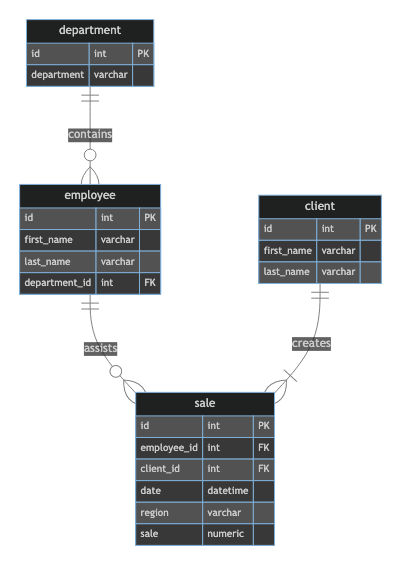
How often do you build and edit Entity Relationship Diagrams? If the answer is ‘more often than I’d like’, and you’re fed up with tweaking your diagrams, take <5 minutes to read my latest article on building your diagrams with code. Track their changes in GitHub, have them build as part of your CI/CD pipeline, and even drop them into your dbt docs if you like.
This is a ‘friends and family’ link, so it’ll bypass the usual Medium paywall.
I’m not affiliated to the tool I’ve chosen in any way. Just like how it works.
Let me know yours thoughts!
There are many of these already as well: https://modeling-languages.com/text-uml-tools-complete-list/
This is a good first step. The next step is to think about dependencies in the build process; to what degree can the diagram be used to implement the rest of the system?
One difficulty with using Mermaid this way is a loss of machine-readable formal information. Mermaid is focused on markup and cosmetics, which is great for presentation, but not great for machine-readability. I don’t know if there are any better alternatives, though; it’s not common for presentation formats to have machine-readable structures.
UML can be compiled to code using some tools, would that address this? Or is your thought that it would build code and push to production systems?
UML is an interesting case; I think that UML Structure diagrams can be compiled, but not the others. This is because UML describes both buildtime and runtime connections between entities, and specifying runtime entities with UML runs into declarative existential claims which are not obviously compilable into static code.
In any case, I’m only thinking about the build step. I think modern applications should be chimeric; they should be built from many modules written in many languages. For example, many compilers and interpreters include at least one page of Zephyr ASDL, which is excellent for the singular task of describing ASTs and ADTs but not anything else.
Great point. We use this for our solution design docs, and to display the final star schema in our dbt models that we then embed within our dbt docs. Given we use dbt for our warehouse, we don’t need to worry about the create table statements.
How is a “diagram as code” not machine readable?
I’m talking specifically about Mermaid. Something like DOT is slightly better. The ultimate goal is to extract the formal structure. For Mermaid or DOT, this extraction requires a text parser and a walk over an AST; it’s about half of a compiler!
This might not sound like a problem compared to something like PBs or JSON, which also require something that looks like a parser and a tree-walker. The difference is in the tooling; the DOT tools can’t directly yank a DAG from a file or iterate over its edges, but
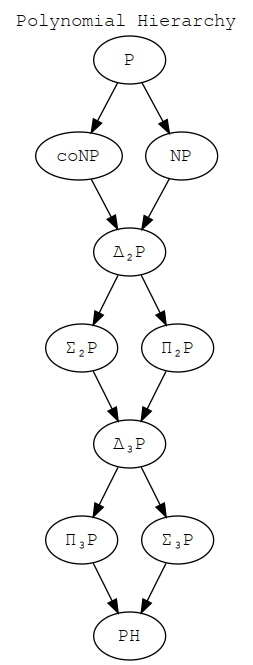
jqcan do that for DAGs encoded in JSON.For a complete worked example, consider this tool which combines JSON and DOT. It produces diagrams that look like this image by building a DAG, packing the DAG into JSON, compiling the DAG to DOT, compiling the DOT into a PNG, and finally packing the JSON into a custom PNG chunk. This workflow itself is a DAG! The JSON is in the PNG:
$ nix build $ result/bin/zaha json complexity/decision/hierarchy/polynomial.png {"labels": ["P", "coNP", "NP", "\u0394\u2082P", "\u03a3\u2082P", "\u03a0\u2082P", "\u0394\u2083P", "\u03a0\u2083P", "\u03a3\u2083P", "PH"], "structure": 28074104194051, "title": "Polynomial Hierarchy"}And then I can use this tool to help write a book. In these build instructions, I call
zahaseveral times to prepare some JSON, then usejqand Python to build some tables and emit some Markdown.
{kind=link}