The pattern is this…
- 2FA is added to code, not well tested, and bugs go on for a long period with no concern to ‘nip them in the bud’ while code experience is fresh
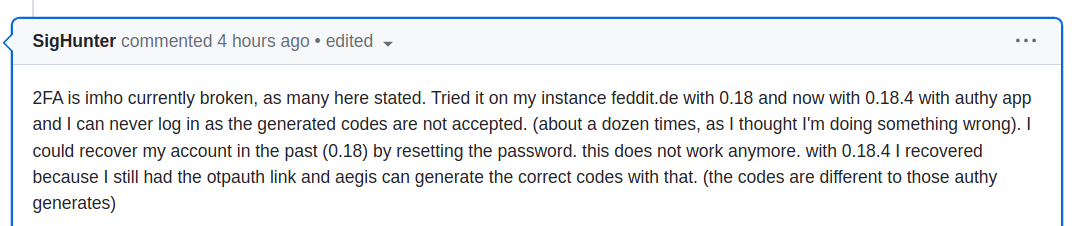
- The same thing happened with munging of “&” in title of post and code blocks of comments.
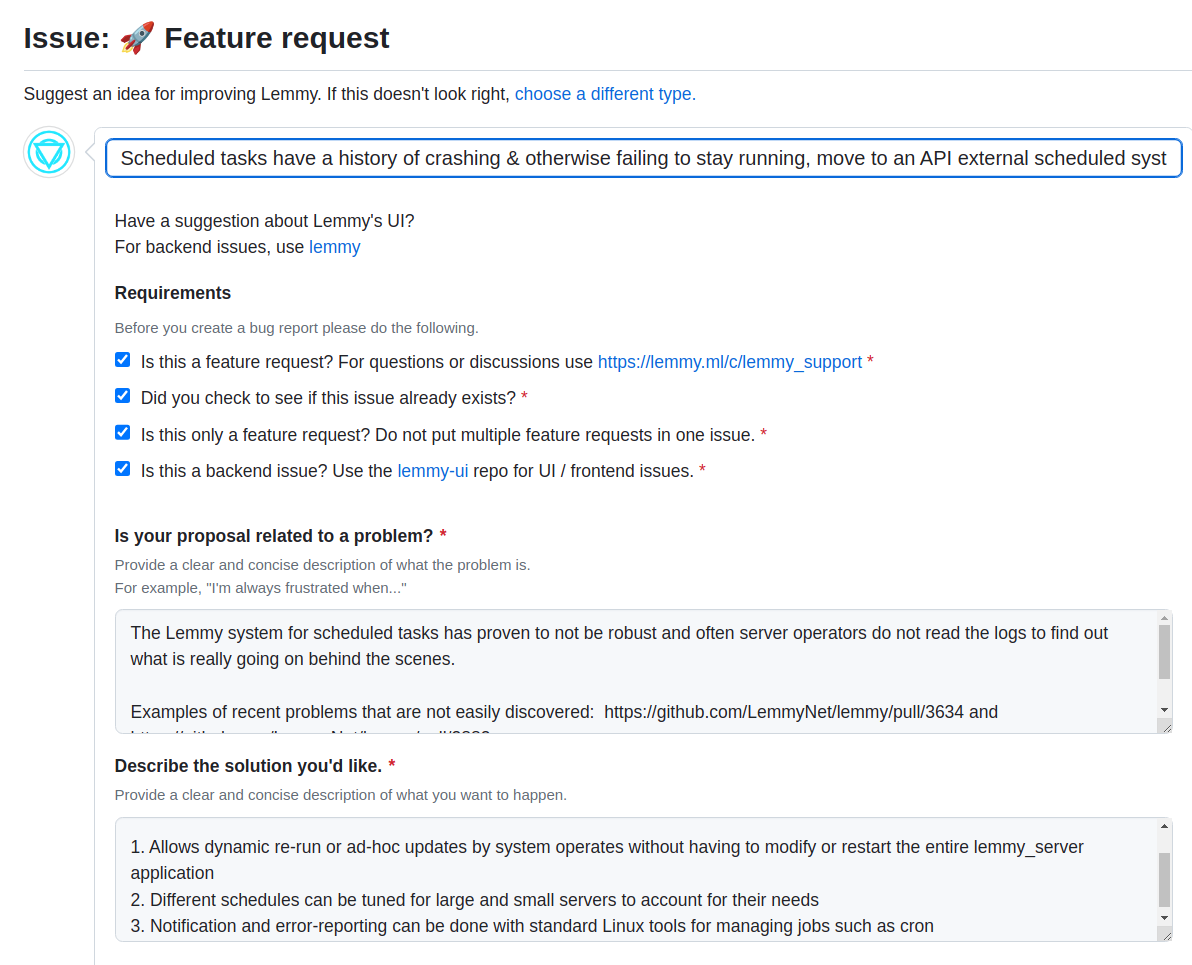
I think we should look at the whole situation as a blessing that not-logged-in/anonymous users consistently performs perfectly fine. I’ve tried over 10 million posts, and it scales well. It works for a single community, it works for All.
If I were integrating API response caching, I would focus on that same aspect. Listing /c/memes by Active for up to 20 pages of 50 length, 1000 posts, would be a cache-worthy dataset. Then offload filtering to an independent DBMS, in-memory application code, or even the client-side code.
The tricky Lemmy usage case tends to be: 1) listing a profile beaks all rules about community data and even time-based organization. But it is the same output, basically static. For those reasons, it is a candidate to cache slow-path on rebuild, restrict during high concurrency/server nearing overload. 2) listing multiple communities between All and Nothing. Blending communities, even from remote API responses, is always going to be tricky for cache attempts. 3) situations where a lot of blocking of instance or community gets a particular user into basically a custom sort order and post listing.
Basic here…
-
we could archive out old data
-
we could create parallel tables or materialized views and maintain a table of new data.
Lemmy really pushes the idea of data being presented backwards, forwards, filtered, sliced, diced, every way. It favors having a smaller set of data.
If you are going to have all this dynamic merging of communities, cherry-picking which communities, person to person blocking, flags like NSFW filtering thrown in at any time… you need a concept of data walls on how much data. Especially with the ORM overhead at play.
-
The index usage of post is all wrong, wrong thinking…
CREATE INDEX idx_post_aggregates_featured_community_active ON public.post_aggregates USING btree (featured_community DESC, hot_rank_active DESC, published DESC);
CREATE INDEX idx_post_aggregates_featured_community_controversy ON public.post_aggregates USING btree (featured_community DESC, controversy_rank DESC);
SELECT ends with…
ORDER BY “post_aggregates”.“featured_community” DESC , “post_aggregates”.“hot_rank_active” DESC , “post_aggregates”.“published” DESCthey created compound indexes based on how ORDER BY is used. But there is a maximum page length of 50 posts. So really that is only helping with sorting 50 posts each SQL SELECT.
INDEX needs to be the heart of WHERE clause. Not ORDER BY hot_rank_active, and LIMIT 50. The hot_rank_active could have been put into the WHERE clause, but it wasn’t.