Lemmy’s PostgreSQL was developed with this philosophy, intentional or otherwise:
-
Real-time client connection and notification via websocket that gets every single action that passes through PostgreSQL. One upvote, instantly sent to client. One new comment, instantly appeared on Lemmy-ui with version 0.17.4
-
INSERT overhead for PostgreSQL. As soon as a Lemmy post or comment is done, a parallel post_aggregate and comment_aggregate row is created.
-
INSERT counting overhead. Extreme effort is made by Lemmy to count things, all the time. Every new INSERT of a comment or post does a real-time update of the total server count. This is done via a SQL UPDATE and not by just issuing a COUNT(*) on the rows when the data is requested.
-
No archiving or secondary storage concept. PostgreSQL has it in the main tables or nothing.
-
Raw numbers, local and unique for each instance, for comment and post. But community name and username tend to be more known than raw numbers.
-
Sorting choices presented on many things: communities, posts, comments. And new methods of sorting and slicing the data keep being added in 2023.
-
No caching of data. The developers of lemmy have gone to extremes to avoid caching on either lemmy-ui or within the Rust code of lemmy_server. Lemmy philosophy favors putting constant connection to a single PostgreSQL.
-
User preferences and customization are offloaded to PostgreSQL do do the heavy lifting. PostgreSQL has to look at the activity of each user to know if they have saved a post, previously read a post, upvoted that post, or even blocked the person who created the post.
-
Language choice is built into the system early, but I see no evidence it has proven to be useful. But it carries a high overhead in how many PostgreSQL database rows each site carries - and is used in filtering More often than not, I’ve found end-users confused why they can’t find content when they accidentally turned off choices in lemmy-ui
-
All fields on SELECT. Throughout the Rust Diesel ORM code, it’s every field in every table being touched.
-
SELECT statements are almost always ORM machine generated. TRIGGER FUNCTION logic is hand-written.
Counting is done on each new INSERT, but on the SELECT side of things there are some background batch jobs. Most notable:
/// Update the hot_rank columns for the aggregates tables /// Runs in batches until all necessary rows are updated once fn update_hot_ranks(conn: &mut PgConnection) { info!("Updating hot ranks for all history..."); process_hot_ranks_in_batches( conn, "post_aggregates", "a.hot_rank != 0 OR a.hot_rank_active != 0", "SET hot_rank = hot_rank(a.score, a.published), hot_rank_active = hot_rank(a.score, a.newest_comment_time_necro)", ); process_hot_ranks_in_batches( conn, "comment_aggregates", "a.hot_rank != 0", "SET hot_rank = hot_rank(a.score, a.published)", ); process_hot_ranks_in_batches( conn, "community_aggregates", "a.hot_rank != 0", "SET hot_rank = hot_rank(a.subscribers, a.published)", ); info!("Finished hot ranks update!"); }This is done every 15 minutes by the Rust code internally.
function as of version 0.18.4
CREATE FUNCTION public.hot_rank(score numeric, published timestamp without time zone) RETURNS integer LANGUAGE plpgsql IMMUTABLE PARALLEL SAFE AS $$ DECLARE hours_diff numeric := EXTRACT(EPOCH FROM (timezone('utc', now()) - published)) / 3600; BEGIN IF (hours_diff > 0) THEN RETURN floor(10000 * log(greatest (1, score + 3)) / power((hours_diff + 2), 1.8))::integer; ELSE RETURN 0; END IF; END; $$;Rust function:
// Runs the hot rank update query in batches until all rows have been processed. /// In `where_clause` and `set_clause`, "a" will refer to the current aggregates table. /// Locked rows are skipped in order to prevent deadlocks (they will likely get updated on the next /// run) fn process_hot_ranks_in_batches( conn: &mut PgConnection, table_name: &str, where_clause: &str, set_clause: &str, ) { let process_start_time = NaiveDateTime::from_timestamp_opt(0, 0).expect("0 timestamp creation"); let update_batch_size = 1000; // Bigger batches than this tend to cause seq scans let mut processed_rows_count = 0; let mut previous_batch_result = Some(process_start_time); while let Some(previous_batch_last_published) = previous_batch_result { // Raw `sql_query` is used as a performance optimization - Diesel does not support doing this // in a single query (neither as a CTE, nor using a subquery) let result = sql_query(format!( r#"WITH batch AS (SELECT a.id FROM {aggregates_table} a WHERE a.published > $1 AND ({where_clause}) ORDER BY a.published LIMIT $2 FOR UPDATE SKIP LOCKED) UPDATE {aggregates_table} a {set_clause} FROM batch WHERE a.id = batch.id RETURNING a.published; "#, aggregates_table = table_name, set_clause = set_clause, where_clause = where_clause )) .bind::(previous_batch_last_published) .bind::(update_batch_size) .get_results::(conn); match result { Ok(updated_rows) => { processed_rows_count += updated_rows.len(); previous_batch_result = updated_rows.last().map(|row| row.published); } Err(e) => { error!("Failed to update {} hot_ranks: {}", table_name, e); break; } } } info!( "Finished process_hot_ranks_in_batches execution for {} (processed {} rows)", table_name, processed_rows_count ); }
The general problem of scalability that lemmy_server is facing:
comment and post are endless tables, and over 500,000 posts in a single community and join logic can go into nonsense states where it does not age out old content.
Almost all the sorting orders can basically be considered filtering choices too. But the SQL doesn’t treat it that way, and tries to use LIMIT and paging as a filter without really doing so.
Aren’t almost ALL of the ‘useful’ sorts that a person using Lemmy would want… “recent”. how often do you really need to sort by “Old”?
Problem post sorts, Aged
- Old
- Most Comments
- Top All Time
- Top Year
Aren’t all others based on recency in one form or another?
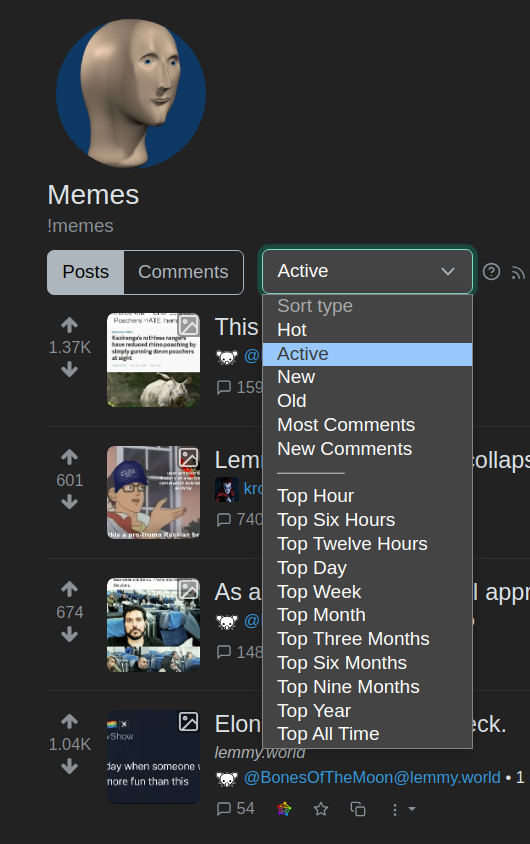
Screenshot of the sort choices in 0.18.4 on lemmy.ml for a single community:
This comment branch is about dullbanana’s proposed rewrite of JOIN logic for listing of lemmy post
SELECT “post”.“id”, “post”.“name”, “post”.“url”, “post”.“body”, “post”.“creator_id”, “post”.“community_id”, “post”.“removed”, “post”.“locked”, “post”.“published”, “post”.“updated”, “post”.“deleted”, “post”.“nsfw”, “post”.“embed_title”, “post”.“embed_description”, “post”.“thumbnail_url”, “post”.“ap_id”, “post”.“local”, “post”.“embed_video_url”, “post”.“language_id”, “post”.“featured_community”, “post”.“featured_local”, “person”.“id”, “person”.“name”, “person”.“display_name”, “person”.“avatar”, “person”.“banned”, “person”.“published”, “person”.“updated”, “person”.“actor_id”, “person”.“bio”, “person”.“local”, “person”.“private_key”, “person”.“public_key”, “person”.“last_refreshed_at”, “person”.“banner”, “person”.“deleted”, “person”.“inbox_url”, “person”.“shared_inbox_url”, “person”.“matrix_user_id”, “person”.“admin”, “person”.“bot_account”, “person”.“ban_expires”, “person”.“instance_id”, “community”.“id”, “community”.“name”, “community”.“title”, “community”.“description”, “community”.“removed”, “community”.“published”, “community”.“updated”, “community”.“deleted”, “community”.“nsfw”, “community”.“actor_id”, “community”.“local”, “community”.“private_key”, “community”.“public_key”, “community”.“last_refreshed_at”, “community”.“icon”, “community”.“banner”, “community”.“followers_url”, “community”.“inbox_url”, “community”.“shared_inbox_url”, “community”.“hidden”, “community”.“posting_restricted_to_mods”, “community”.“instance_id”, “community”.“moderators_url”, “community”.“featured_url”,
EXISTS (SELECT “community_person_ban”.“id”, “community_person_ban”.“community_id”, “community_person_ban”.“person_id”, “community_person_ban”.“published”, “community_person_ban”.“expires” FROM “community_person_ban” WHERE ((“post_aggregates”.“community_id” = “community_person_ban”.“community_id”) AND (“community_person_ban”.“person_id” = “post_aggregates”.“creator_id”))),
“post_aggregates”.“id”, “post_aggregates”.“post_id”, “post_aggregates”.“comments”, “post_aggregates”.“score”, “post_aggregates”.“upvotes”, “post_aggregates”.“downvotes”, “post_aggregates”.“published”, “post_aggregates”.“newest_comment_time_necro”, “post_aggregates”.“newest_comment_time”, “post_aggregates”.“featured_community”, “post_aggregates”.“featured_local”, “post_aggregates”.“hot_rank”, “post_aggregates”.“hot_rank_active”, “post_aggregates”.“community_id”, “post_aggregates”.“creator_id”, “post_aggregates”.“controversy_rank”, “community_follower”.“pending”,
EXISTS (SELECT “post_saved”.“id”, “post_saved”.“post_id”, “post_saved”.“person_id”, “post_saved”.“published” FROM “post_saved” WHERE ((“post_aggregates”.“post_id” = “post_saved”.“post_id”) AND (“post_saved”.“person_id” = $1))),
EXISTS (SELECT “post_read”.“id”, “post_read”.“post_id”, “post_read”.“person_id”, “post_read”.“published” FROM “post_read” WHERE ((“post_aggregates”.“post_id” = “post_read”.“post_id”) AND (“post_read”.“person_id” = $2))),
EXISTS (SELECT “person_block”.“id”, “person_block”.“person_id”, “person_block”.“target_id”, “person_block”.“published” FROM “person_block” WHERE ((“post_aggregates”.“creator_id” = “person_block”.“target_id”) AND (“person_block”.“person_id” = $3))), “post_like”.“score”, coalesce((“post_aggregates”.“comments” - “person_post_aggregates”.“read_comments”), “post_aggregates”.“comments”)
FROM (((((((“post_aggregates”
INNER JOIN “person” ON (“post_aggregates”.“creator_id” = “person”.“id”))
INNER JOIN “community” ON (“post_aggregates”.“community_id” = “community”.“id”))
INNER JOIN “post” ON (“post_aggregates”.“post_id” = “post”.“id”)) LEFT OUTER JOIN “community_follower” ON ((“post_aggregates”.“community_id” = “community_follower”.“community_id”) AND (“community_follower”.“person_id” = $4)))
LEFT OUTER JOIN “community_moderator” ON ((“post”.“community_id” = “community_moderator”.“community_id”) AND (“community_moderator”.“person_id” = $5)))
LEFT OUTER JOIN “post_like” ON ((“post_aggregates”.“post_id” = “post_like”.“post_id”) AND (“post_like”.“person_id” = $6)))
LEFT OUTER JOIN “person_post_aggregates” ON ((“post_aggregates”.“post_id” = “person_post_aggregates”.“post_id”) AND (“person_post_aggregates”.“person_id” = $7)))
WHERE (((((((((“community”.“removed” = $8) AND (“post”.“removed” = $9)) AND (“post_aggregates”.“community_id” = $10)) AND ((“community”.“hidden” = $11) OR (“community_follower”.“person_id” = $12))) AND (“post”.“nsfw” = $13)) AND (“community”.“nsfw” = $14))
AND EXISTS (SELECT “local_user_language”.“id”, “local_user_language”.“local_user_id”, “local_user_language”.“language_id” FROM “local_user_language” WHERE ((“post”.“language_id” = “local_user_language”.“language_id”) AND (“local_user_language”.“local_user_id” = $15))))
AND NOT (EXISTS (SELECT “community_block”.“id”, “community_block”.“person_id”, “community_block”.“community_id”, “community_block”.“published” FROM “community_block” WHERE ((“post_aggregates”.“community_id” = “community_block”.“community_id”) AND (“community_block”.“person_id” = $16)))))
AND NOT (EXISTS (SELECT “person_block”.“id”, “person_block”.“person_id”, “person_block”.“target_id”, “person_block”.“published” FROM “person_block” WHERE ((“post_aggregates”.“creator_id” = “person_block”.“target_id”) AND (“person_block”.“person_id” = $17)))))
ORDER BY “post_aggregates”.“featured_community” DESC , “post_aggregates”.“hot_rank_active” DESC , “post_aggregates”.“published” DESC
LIMIT $18 OFFSET $19
parameters: $1 = ‘3’, $2 = ‘3’, $3 = ‘3’, $4 = ‘3’, $5 = ‘3’, $6 = ‘3’, $7 = ‘3’, $8 = ‘f’, $9 = ‘f’, $10 = ‘24’, $11 = ‘f’, $12 = ‘3’, $13 = ‘f’, $14 = ‘f’, $15 = ‘2’, $16 = ‘3’, $17 = ‘3’, $18 = ‘20’, $19 = ‘0’
With all the INSERT overhead, I feel like the other-end of SELECT isn’t leveraging it.
comment to comment_aggregates has a pure one to one relationship… it may as well be just more columns on the original comment table.
same with post and post_aggregates and community + community_aggregates
It leads to concerns if a SQL SELECT is joining community_id of a post to the aggregate or the real, given how desired attributes may be mixed and duplicated on both.
A single new post or single new comment does real-tine UPDATE counting 3 different times: one UPDATE for the server, one UPDATE for the community, one UPDATE for the person. This is all part of the overhead of an end-user adding one new post or comment.