
1·
6 days agoWhy did De Niro immediately pop into my head?
Oh, yeah…
I’ve got nipples, Greg, could you milk me?
Why did De Niro immediately pop into my head?
Oh, yeah…
I’ve got nipples, Greg, could you milk me?

But, I thought Trump was all about state’s rights? This is very confusing. /s
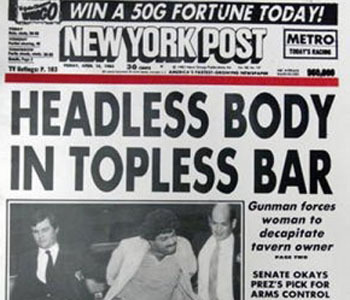
Maybe he should have removed the python the first time he found him in his toilet?
Lifts lid, yep, he’s still there
/s just something about the wording of the title sounded funny

I’ve been tempted to ditch my current password manager and move to bitwarden. I think this is the final push I needed.

Bench warrant, let’s do this!

If you go, definitely stay at Four Seasons Total Landscaping next door, best accommodations around and their convention spaces are great for any press conferences you might need to hastily put together.
I used to think they were bots. I still do, but I used to, too.
Imagine how good it will feel to let them waste all their money and lose! Go make it happen. VOTE!

Similar to previous reply about MATE with font size changes, I do that with plasma. I hadn’t seen plasma big screen you linked, I’ll definitely try that one out. I’ve wondered about https://en.m.wikipedia.org/wiki/Plasma_Mobile? Like these sort of niche projects don’t always get a lot of attention, if the bigscreen project doesn’t work out, I’d bet the plasma mobile project is fairly active and given the way it scales for displays might work really well on a tv
Speaking of scaling since you mentioned it. I have noticed scaling in general feels a lot better in Wayland. If you’d only tried it in X11 before, might want to see if Wayland works better for you.

First a caveat/warning - you’ll need a beefy GPU to run larger models, there are some smaller models that perform pretty well.
Adding a medium amount of extra information for you or anyone else that might want to get into running models locally
If you look at https://ollama.com/library?sort=featured you can see models
Model size is measured by parameter count. Generally higher parameter models are better (more “smart”, more accurate) but it’s very challenging/slow to run anything over 25b parameters on consumer GPUs. I tend to find 8-13b parameter models are a sort of sweet spot, the 1-4b parameter models are meant more for really low power devices, they’ll give you OK results for simple requests and summarizing, but they’re not going to wow you.
If you look at the ‘tags’ for the models listed below, you’ll see things like 8b-instruct-q8_0 or 8b-instruct-q4_0. The q part refers to quantization, or shrinking/compressing a model and the number after that is roughly how aggressively it was compressed. Note the size of each tag and how the size reduces as the quantization gets more aggressive (smaller numbers). You can roughly think of this size number as “how much video ram do I need to run this model”. For me, I try to aim for q8 models, fp16 if they can run in my GPU. I wouldn’t try to use anything below q4 quantization, there seems to be a lot of quality loss below q4. Models can run partially or even fully on a CPU but that’s much slower. Ollama doesn’t yet support these new NPUs found in new laptops/processors, but work is happening there.
It’s a good thing that real open source models are getting good enough to compete with or exceed OpenAI.
The Moon is a Harsh Mistress - by Heinlein who also wrote Starship Troopers. Starship Troopers is also great and pretty different from the movie

I’ll preface by saying I think LLMs are useful and in the next couple years there will be some interesting new uses and existing ones getting streamlined…
But they’re just next word predictors. The best you could say about intelligence is that they have an impressive ability to encode knowledge in a pretty efficient way (the storage density, not the execution of the LLM), but there’s no logic or reasoning in their execution or interaction with them. It’s one of the reasons they’re so terrible at math.

I like the game, but agree with the over-tutorialed complaints. They have two difficulty modes, I wish only story mode got all the handholding. I think there’s enough obvious indicators to get you through all the game mechanics.

It has been on my list to figure out how to move to forgejo, need to do it soon before the migration process breaks or gets awful.

The Beats Fit Pros are nice. I don’t do a ton of exercise in them but think they’d handle all the issues you mentioned pretty well.

Coming from c# then typescript and nextjs, rye feels very intuitive and like a nice bridge / gateway drug into python.


DNFTA